
スキャンした文書PDFファイルを、あとから編集したいと考えたことはありませんか?
ただ、PDFファイルはテキスト形式ではないため文字の編集ができません。
ここでは、スキャンしたPDFファイルのテキストを文字認識させる方法や、役立つフリーソフトをご紹介します。
スキャンで作ったPDFの文字認識を可能にするOCR処理

OCRとは、Optical Character Readerのことです。
スキャンした文書をデジタルの文字コードへ変換する技術をOCRと呼んでいます。
通常、スキャンした文書は画像として取り込まれるため、文字の編集ができません。
しかし、OCR処理を行えば、画像として取り込んだ文書の文字をデジタル文字コードへ変換できるため、編集が可能となるのです。
OCRにより編集可能なデータとするには、主に2通りの方法が考えられます。
ひとつは、OCR機能を搭載したスキャナーの使用です。
現在では、複数のメーカーからOCR機能を搭載したスキャナーがリリースされており、スキャニングと同時にOCR処理ができます。
もうひとつの方法は、専用のソフトやツールを使用し、取り込んだデータにOCR処理を施す方法です。
OCR機能付きのスキャナーをお持ちでないのなら、こちらの方法がおすすめです。
>スキャンしたデータや文書を編集したい!OCR活用術をご紹介
Adobe Acrobatを使った文字認識の方法
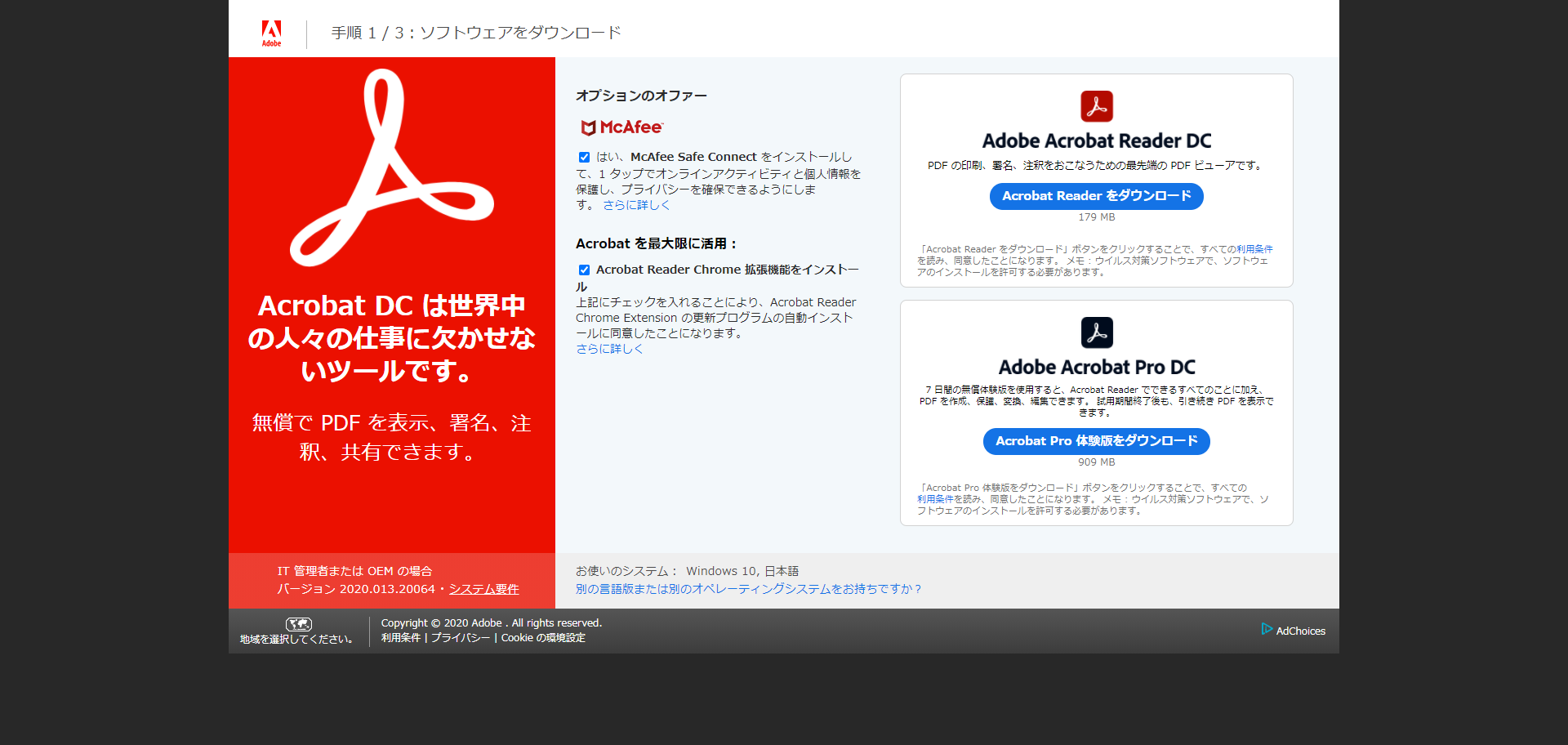
Adobe SystemsのAdobe Acrobatを使用すれば、スキャンしたデータの文字認識が可能です。
ここでは、Adobe Acrobatを使用して文字認識させる方法を、2通りご紹介しましょう。
スキャン時にOCR処理されたPDFファイルを生成する
まずは、Adobe Acrobatを起動し[ファイル]→[作成]→[スキャナー]と進みPDFを選択しましょう。
使用しているスキャナーの名前が表示されているのを確認し、[カラー写真]以外を選択してください。
設定アイコンをクリック後、[テキスト認識(OCR)]にチェックが入っていることを確認しましょう。
[テキスト認識(OCR)]のアイコンをクリックし、[文書の言語]→[出力]→[OK]をクリックします。
[スキャン]→[スキャンの完了]→[OK]で作業は終了です。
スキャン済みのPDFデータにOCRを適用する
すでにスキャニングしている文書にOCR処理を行う方法です。
Acrobatを起動し、対象のファイルを開きましょう。
[ツール]→[スキャン補正]→[テキスト認識]→[このファイル内]を選んでください。
第二ツールバーからOCR処理を施すページを指定します。
[設定]から文書の言語や出力形式などを指定し、[OK]をクリックしましょう。
出力形式の選択では、[検索可能な画像]、[検索可能な画像(非圧縮)]、[編集可能なテキストと画像][CliarScan]などから選べます。
すべての設定が終わったら、[OK]をクリックしてOCR処理を完了します。
PDFのOCR処理ができるフリーソフト
ここからは、PDFのOCR処理ができるフリーソフトをいくつかご紹介します。
どれもおすすめのツールですが、それぞれに特徴があり操作性や機能が異なります。
使いやすいと感じるものを選んで試してみましょう。
Light PDF
オンラインで利用できるPDF編集ツールです。
PDFの編集以外にも、フォーマット変換やOCR処理などさまざまな機能を備えています。
面倒な登録や手続きも不要で、思い立ったときすぐ利用できる手軽さが魅力です。
無料版は、認識できる言語が1つだけのため、文書に異なる言語が混在しているケースではうまく変換できません。
また、txtファイルへの変換しかできないため、注意が必要です。
異なる言語が混在する文書にOCR処理を施したい、txt以外のファイルで出力したいといった場合は、有償版の利用を検討してみましょう。
出典:Light PDF公式
Online OCR
PDFやJPEG、PNG、GIFなどさまざまなデータのOCR処理が可能なフリーソフトです。
登録せず無料利用できますが、利用登録すると処理できるファイルサイズが15MBから最大200MBに広がります。
入力形式や出力形式の幅も広がるため、登録しての利用がおすすめです。
ただ、利用登録をしても変換できるページ数に制限があるため注意が必要です。
最大25ページまでしか処理できず、それ以上は別途料金が発生します。
毎回少ないページ数しか変換しないケースなら、十分活用できるフリーソフトです。
出典:Online OCR
PDFelement
多機能なPDF編集ソフトとして有名です。
PDFの編集やフォーマット変換、作成、電子署名など多機能なソフトで、個人や法人を問わず利用されています。
スキャンしたデータのOCR処理もでき、見えないところへのテキスト情報埋め込みも可能です。
無料版は、PDFelementの公式ホームページからダウンロードできます。
試用期間の制限なく利用できますが、無料版は変換したデータに透かしが入ります。
そのため、重要なビジネス文書には適さない可能性があるため、注意してください。
出典:PDFelement公式
PDFにOCRを適用するメリット

PDFにOCR処理を施すメリットはいくつもありますが、ひとつには検索性の向上が挙げられます。
ファイル形式を変換できるため文字の編集が可能となり、コピー&ペーストができるのもメリットといえるでしょう。
検索可能なため必要なデータの引き出しが容易になる
PDFデータに記載されている文字を認識可能となるため、キーワードによる検索ができます。
そのため、必要に応じてスピーディにデータを取り出せます。
スキャンしたPDFデータは、画像として認識されるため通常はキーワード検索ができません。
そのため、ファイル名や日付などから探すしかできませんが、OCR処理を施せばさまざまなキーワードで検索できます。
過去データの管理や検索が手軽にでき、必要なときスムーズに出力できるのはメリットといえるでしょう。
他のソフトに変換できるので簡単に文書が編集できる
紙文書のまま保管しているケースでは、必要なときに書類が見つからないこともあります。
あらかじめ紙の文書をスキャンしてOCR処理を施し、WordやExcelファイルへ変換しておけば、いつでも編集や出力が可能です。
わざわざ文書をいちから作り直す手間を省け、業務効率の向上が期待できます。
コピー&ペーストができるので過去データを活用しやすい
過去に作成した文書のデータを引用したいシーンは多々あります。
しかし、紙文書のままでは、いちから手作業で打ち込まねばならず、手間がかかります。
同じく、PDFで保存しているデータでも、コピー&ペーストができないため手間と労力がかかってしまうのです。
PDFにOCR処理を施しておけば、コピー&ペーストが可能です。
そのため、過去文書からデータの引用も簡単にでき、作業者の手間を大幅に軽減できます。
スキャンサービスの一括OCRスキャンがおすすめ
スキャンサービスを利用すれば、大量の文書をまとめて電子化できるほか、一括でのOCR処理も可能です。
電子化したい文書が大量にあり、なおかつまとめてOCRもしたいのであれば、スキャンサービスの利用を検討してみましょう。





